We probably know that feeling: A GPU cluster has been running for 40 hours straight — training a model, simulating molecules, or rendering high-res frames. Everything looks perfect… until one small “pop” from the power supply silences the rack.
The screens freeze. The fans slow down. And all that compute power is suddenly useless.
Redundancy, Explained the Way Engineers See It
Think of a redundant PSU setup as a jet with twin engines. One does the flying; the other stands by in case something goes wrong — and when it does, it kicks in so seamlessly that passengers never notice.
In the same way, a 1+1 or N+1 redundant PSU keeps your GPUs running even if one module fails. The backup instantly takes over the power load — no reboot, no data loss, no panic at 2 a.m.
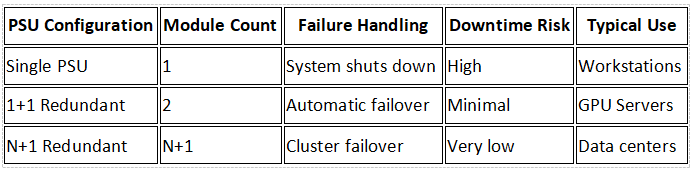

Simple in theory — but engineering it into a dense GPU chassis is anything but simple. Redundancy changes how you design everything: airflow paths, module bays, even cable routing.
Designing Reliability from the Metal Up
A redundant PSU only works if the chassis is built to support it. Add a second module, and you’re adding heat, density, and design constraints. Without precise airflow management, redundancy can actually reduce stability.
That’s why OneChassis approaches this from an engineering-first perspective. Each GPU case is laid out to preserve cooling efficiency, tool-less maintenance, and clean cable routing — even with dual or triple PSU configurations.
Take the OneChassis OCG5800A-5H12-L, for example. This 5U GPU server chassis supports multiple CRPS (Common Redundant Power Supply) modules, allowing both 1+1 and N+1 redundancy without choking airflow. Hot-swappable PSU bays and modular fan placement make service fast and safe — exactly what you need when uptime is non-negotiable.

Real-World Reliability in Action
Now, let’s see how that engineering translates to the real world — through three real cases that show how GPU server chassis evolve from basic redundancy and maintainability, to high-density stability, and finally, to multi-node scalability that drives long-term reliability and operational efficiency.
Case 1: Building the Foundation —Power Redundancy That Prevents Downtime
At a regional AI service provider, a single PSU failure once brought down half a training rack mid-epoch. After moving to OneChassis 4U GPU cases with dual CRPS modules, the first noticeable difference wasn’t just uptime — it was silence. When a PSU failed again months later, the backup module took over instantly. The server’s LEDs didn’t even flicker.
But what made this setup valuable wasn’t only redundancy — it was how maintainable it became. Technicians could hot-swap the failed PSU from the front panel without pulling the chassis out of the rack. That single improvement cut mean time to repair (MTTR) by over 80%.
This stage established the foundation: uninterrupted power and fast maintenance — the first layer of reliability.
Case 2: Managing Heat and Density —Redundancy Meets Airflow Intelligence
As systems scale, redundancy introduces new challenges — especially heat. In a university HPC lab running dense 8-GPU servers, dual PSUs used to create thermal hotspots at the rear of the chassis, pushing fan speeds (and noise) to the limit.
OneChassis engineers tackled this with adaptive airflow zoning inside sthe OCG5800A-5H12-L. By offsetting PSU modules and integrating split-flow ventilation, the hot air from the redundant units was redirected away from GPU intakes.
The result wasn’t just cooler operation — it was sustained performance stability across long, compute-heavy workloads.

This proved that redundancy and cooling don’t have to fight each other — if the chassis is engineered to handle both in harmony.
Case 3: Scaling Reliability —Multi-Node Maintenance Without Interruption
Redundancy isn’t just about surviving a single failure anymore. In large GPU clusters, it’s about continuous operation during scaling and servicing.
A rendering company in Vancouver faced exactly that challenge. As their GPU farm expanded, swapping or upgrading PSU modules across 40+ nodes risked major downtime. Using OneChassis 8U modular GPU cases, they implemented a clustered PSU redundancy model — where individual nodes could be serviced live without interrupting the cluster’s workload.
Technicians could isolate one chassis, swap a PSU or fan tray, and bring it back online in minutes — all while render jobs across the rack continued seamlessly.
This is where reliability grows beyond a single box. It becomes systemic — redundancy designed at both the component and cluster level.
“We used to fear maintenance windows,” one of their IT leads said. “Now, the system just keeps breathing.”
From Hardware Feature to Design Philosophy
Across industries, the story repeats — AI, biotech, rendering, data analytics. Each began with a single need: “don’t go down.” But as systems evolved, redundancy became not just a feature, but a design mindset.
That’s what OneChassis builds into every GPU case: reliability from the inside out — from the PSU bay to the airflow path, from cable management to scalability planning.
Because real reliability isn’t built at the end of production. It’s engineered in — right from the metal up.

If you’re architecting your next GPU server or planning a redundant power setup, the OneChassis engineering team is always open to talk —design to design, not sales to customer. Visit www.toponechassis.com or reach out to discuss how we can help optimize redundancy, airflow, and reliability for your build.

 When AI Becomes A Threat, Infrastructure Becomes the Front Line
When AI Becomes A Threat, Infrastructure Becomes the Front Line
 Storage Density Choices in the Same Server Chassis
Storage Density Choices in the Same Server Chassis
 Welcoming 2026: Building the Next Year of AI Infrastructure Together
Welcoming 2026: Building the Next Year of AI Infrastructure Together
 How We Design Thermal Paths: Airflow, Static Pressure & Fan Zones
How We Design Thermal Paths: Airflow, Static Pressure & Fan Zones
