
A Comprehensive Guide to DeepSeek and GPU Server Localization Deployment
Views : 1051
Update time : 2025-02-17 11:32:11
A Comprehensive Guide to DeepSeek and GPU Server Localization Deployment
In today’s data-driven world, businesses and researchers are increasingly relying on advanced AI models like DeepSeek to extract insights, automate processes, and enhance decision-making. However, deploying such models efficiently requires robust hardware infrastructure, particularly GPU servers, to handle the computational demands. This guide will walk you through the step-by-step process of localizing DeepSeek on a GPU server, ensuring optimal performance and scalability.

---
1. Introduction to DeepSeek and GPU Servers
### **What is DeepSeek?**
DeepSeek is a cutting-edge AI model designed for deep learning tasks such as natural language processing, image recognition, and predictive analytics. Its ability to process large datasets and deliver accurate results makes it a valuable tool for industries ranging from healthcare to finance.
Why Use GPU Servers?
GPU (Graphics Processing Unit) servers are essential for running AI models like DeepSeek due to their parallel processing capabilities. Unlike CPUs, GPUs can handle thousands of computations simultaneously, significantly reducing training and inference times. Localizing DeepSeek on a GPU server ensures faster processing, lower latency, and greater control over data privacy.---
2. Prerequisites for Deployment
Before diving into the deployment process, ensure you have the following:
Hardware Requirements
- **GPU Server**: A server equipped with high-performance GPUs (e.g., NVIDIA A100, RTX 3090, or Tesla V100).- **Storage**: Sufficient SSD or NVMe storage for datasets and model files.
- **RAM**: At least 32GB of RAM (64GB or more recommended for large-scale tasks).
- **Cooling System**: Adequate cooling to handle the heat generated by GPUs.
Software Requirements
- **Operating System**: Ubuntu 20.04 LTS or CentOS 7 (recommended for compatibility).- **NVIDIA Drivers**: Latest drivers installed for your GPU.
- **CUDA Toolkit**: Version 11.3 or higher.
- **cuDNN Library**: Optimized for deep learning tasks.
- **Docker**: For containerized deployment (optional but recommended).
- **Python**: Version 3.8 or higher.
---
3. Step-by-Step Deployment Guide
Step 1: Set Up the GPU Server
1. **Install the Operating System**: Begin by installing Ubuntu or CentOS on your server.2. **Update the System**: Run `sudo apt update && sudo apt upgrade` (for Ubuntu) or `sudo yum update` (for CentOS) to ensure all packages are up to date.
3. **Install NVIDIA Drivers**:
- Download the latest drivers from the [NVIDIA website](https://www.nvidia.com/Download/index.aspx).
- Install the drivers using the terminal:
```bash
sudo apt install nvidia-driver-<version>
```
- Reboot the server to apply changes.
Step 2: Install CUDA and cuDNN
1. **Download CUDA Toolkit**:- Visit the [CUDA Toolkit Archive](https://developer.nvidia.com/cuda-toolkit-archive) and select the appropriate version.
- Follow the installation instructions provided by NVIDIA.
2. **Install cuDNN**:
- Download cuDNN from the [NVIDIA Developer Portal](https://developer.nvidia.com/cudnn).
- Copy the files to the CUDA installation directory:
```bash
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
```
Step 3: Set Up Python Environment
1. **Install Python**:```bash
sudo apt install python3.8 python3-pip
```
2. **Create a Virtual Environment**:
```bash
python3 -m venv deepseek-env
source deepseek-env/bin/activate
```
3. **Install Required Libraries**:
```bash
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
pip install transformers datasets
```
Step 4: Download and Configure DeepSeek
1. **Clone the DeepSeek Repository**:```bash
git clone https://github.com/deepseek-ai/deepseek.git
cd deepseek
```
2. **Install Dependencies**:
```bash
pip install -r requirements.txt
```
3. **Configure the Model**:
- Modify the configuration file (`config.yaml`) to specify the number of GPUs, batch size, and other parameters.
- Ensure the model paths and dataset locations are correctly specified.
Step 5: Run DeepSeek on the GPU Server
1. **Start Training or Inference**:- For training:
```bash
python train.py --config config.yaml
```
- For inference:
```bash
python infer.py --config config.yaml
```
2. **Monitor Performance**:
- Use `nvidia-smi` to monitor GPU usage and temperature.
- Optimize performance by adjusting batch size and learning rate.
---
4. Best Practices for Localization
- **Data Security**: Ensure all data is encrypted and access is restricted to authorized personnel.
- **Regular Backups**: Schedule regular backups of model checkpoints and datasets.
- **Scalability**: Use containerization (e.g., Docker) to scale the deployment across multiple servers.
- **Monitoring Tools**: Implement monitoring tools like Prometheus and Grafana to track system performance.
---
5. Troubleshooting Common Issues
- **Driver Compatibility**: Ensure the NVIDIA driver version matches the CUDA toolkit version.
- **Out of Memory Errors**: Reduce batch size or use gradient accumulation.
- **Slow Performance**: Optimize data loading pipelines and enable mixed precision training.
---
6. Conclusion
Deploying DeepSeek on a GPU server is a powerful way to leverage AI capabilities while maintaining control over your infrastructure. By following this guide, you can set up a robust and efficient environment for running DeepSeek, ensuring high performance and scalability. Whether you’re a researcher, developer, or business owner, this localization approach will help you unlock the full potential of AI.
For further assistance, feel free to reach out to our support team or explore our documentation. Happy deploying!
相关新闻
 When AI Becomes A Threat, Infrastructure Becomes the Front Line
When AI Becomes A Threat, Infrastructure Becomes the Front Line
Jan 30,2026
When AI becomes a security risk, infrastructure becomes the front line. Learn how GPU server chassis design affects AI stability, security, and uptime—and how OneChassis builds reliable GPU platforms for enterprise AI workloads.
 Storage Density Choices in the Same Server Chassis
Storage Density Choices in the Same Server Chassis
Jan 16,2026
When building a storage server, many users focus only on total capacity or drive count. In practice, the choice between fewer 3.5″ hard drives and more 2.5″ hard drives has a much deeper impact on performance, reliability, cooling efficiency, and long-term operating cost.
 Welcoming 2026: Building the Next Year of AI Infrastructure Together
Welcoming 2026: Building the Next Year of AI Infrastructure Together
Jan 01,2026
As we step into 2026, the global compute landscape continues to evolve at an unprecedented pace.
AI workloads are denser. GPU clusters are larger. Expectations for stability, efficiency, and scalability are higher than ever.
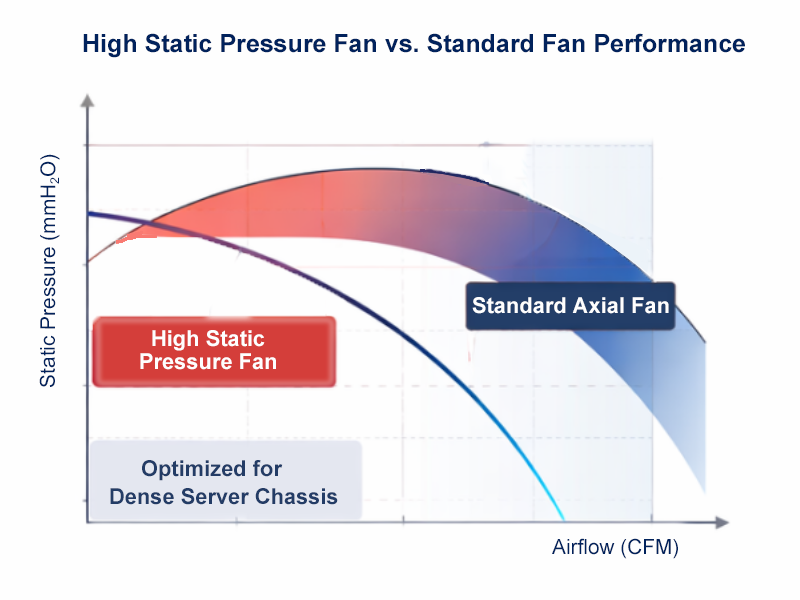 How We Design Thermal Paths: Airflow, Static Pressure & Fan Zones
How We Design Thermal Paths: Airflow, Static Pressure & Fan Zones
Dec 25,2025
In high-density GPU and AI servers, cooling isn’t an accessory — it’s infrastructure.
At OneChassis, thermal design starts at the chassis level. We engineer clear front-to-rear airflow paths to align with data-center cold-aisle / hot-aisle layouts, reducing recirculation and heat buildup under sustained load.
